Use Cases
Strategic Experiments on Pet Supply Brands
This article breaks down how strategic experimentation frameworks are helping pet supply brands turn AI-driven marketing into measurable business growth. Some experiments generated more than 50% revenue lift and double-digit ROAS improvements.

Is Experimentation just A/B Testing?
The biggest misconception in AI marketing is that experimentation simply means testing ad creative or running occasional A/B campaigns. In reality, high-level experimentation is a structured operating system designed to isolate variables, validate hypotheses, and determine which strategies deserve permanent budget allocation.
That framework became especially important for a pet supply ecommerce brand operating across 5 experiments and 4 channels in a single quarter. The business had a large product catalog, recurring purchase behavior, and heavy retention economics, making it an ideal environment for experimentation because even small improvements in targeting quality could compound over time.
And in industries with large SKU catalogs and repeat purchase behavior (especially pet supply ecommerce) this becomes incredibly powerful.

That means even small improvements in targeting quality or customer segmentation compound aggressively over time. Instead of treating campaigns as isolated media buys, the experimentation framework treated the business as a continuous learning system.
What This Experiment Tested
One of the first problems identified was geographic underperformance. Several East Coast markets were declining nearly three times faster than the rest of the business. Existing Google Performance Max campaigns were still using broad “business as usual” targeting, standard platform optimization across all U.S. audiences with generic category segmentation.
The campaigns were spending efficiently, but not intelligently.
To test whether stronger audience calibration could reverse the decline, a second campaign was launched focused specifically on those underperforming East Coast regions.
Instead of broad targeting, the test campaign layered predictive audience signals, top-performing products, and geo-specific intent signals into Performance Max.

The goal was simple: determine whether higher-quality audience inputs could improve incremental business outcomes, not just platform metrics.
The results became visible quickly.
Compared against the control:
- gross profit increased by 59%
- revenue increased by 56%
- order volume increased by 53%
- margin-weighted return on ad spend improved by 15%
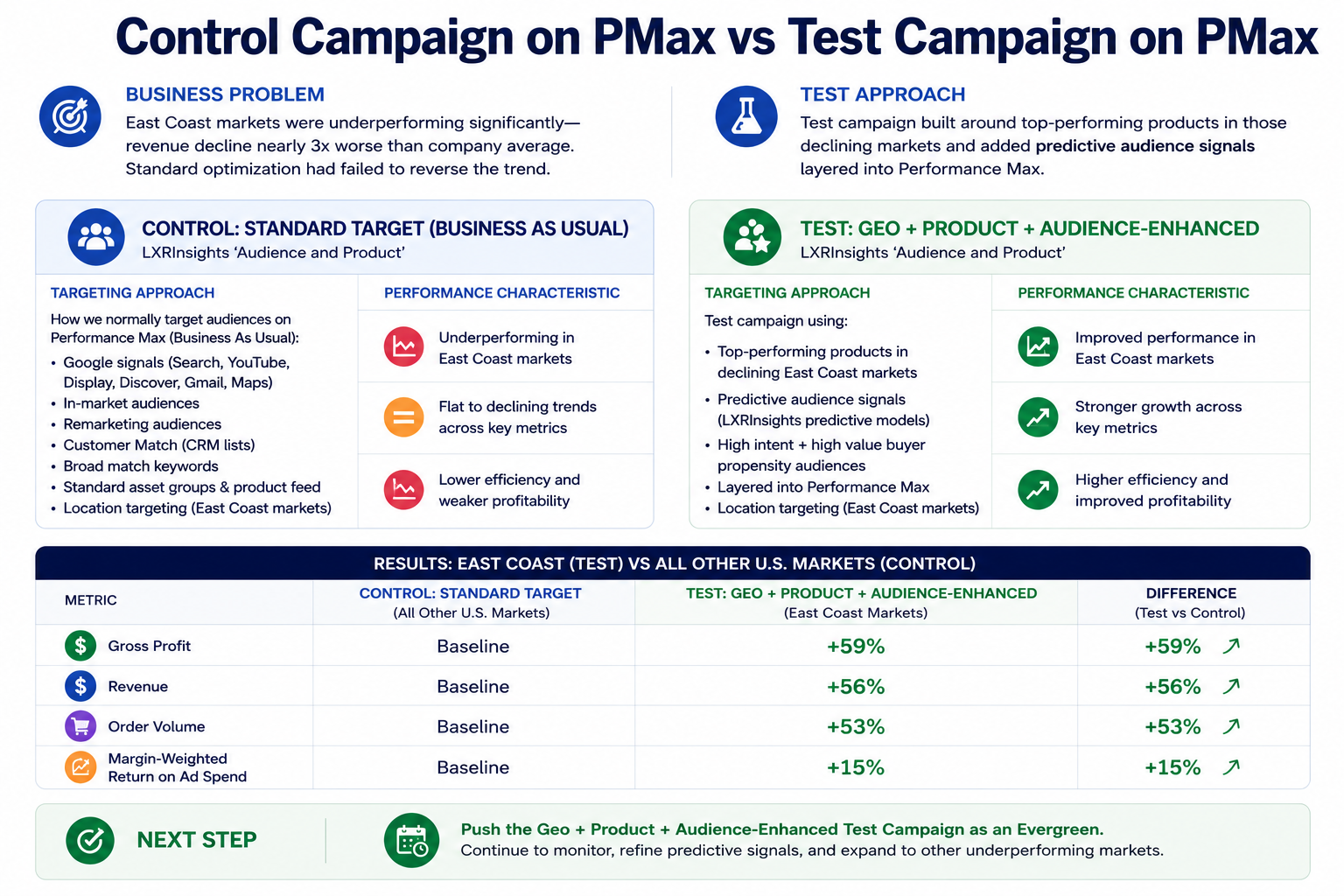
The experiment eventually graduated into an evergreen campaign because the lift was statistically significant and commercially repeatable. That “graduation” moment is one of the most important concepts in strategic experimentation. Most marketers think experiments end when performance improves, but experiments succeed when they become repeatable enough to operationalize permanently. Therefore, the campaign was no longer treated as a temporary test. It became part of the brand’s long-term acquisition infrastructure.
And importantly, the control versus test lines fluctuated throughout the experiment.
That Fluctuation is Normal and Expected.
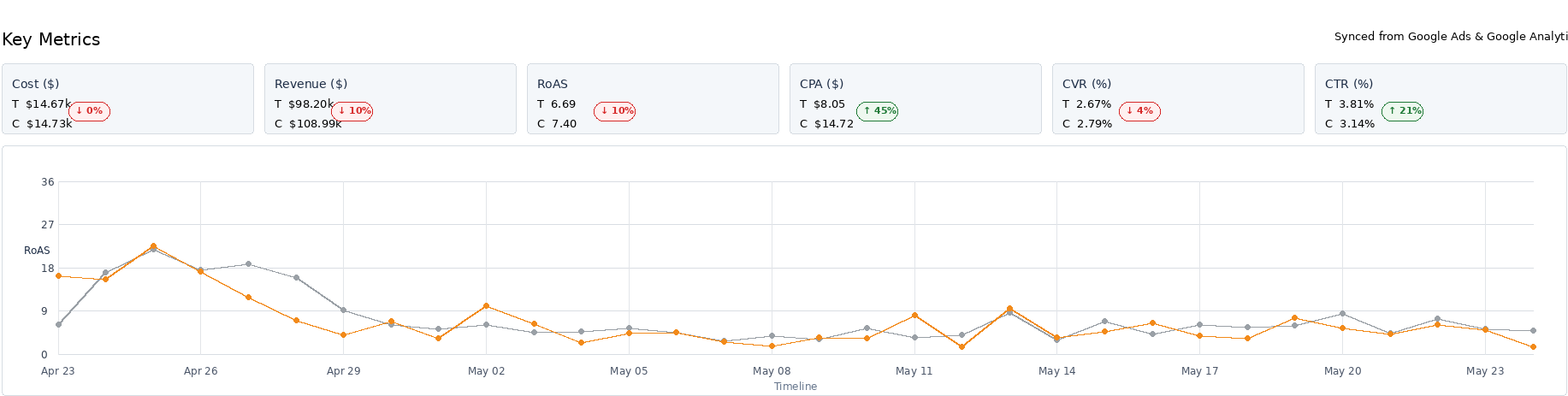
One of the biggest mistakes inexperienced marketers make is assuming the winning campaign should outperform every single day. In reality, especially inside AI-driven systems like Performance Max, volatility exists because the platform is continuously reallocating spend, testing inventory, adjusting auction participation, and optimizing across changing user behavior patterns. What matters is directional performance over time and whether the statistical confidence becomes strong enough to confirm the lift is real instead of random variance.
This is why experimentation frameworks require:
- control groups
- time-based measurement
- sufficient data volume
- confidence thresholds
- incremental lift validation
Quality Audience Testing
Another active experiment focused on “quality audiences” for racing supply products.
The hypothesis behind this test was that predictive audience segmentation could improve acquisition efficiency by feeding higher-intent users into the campaign compared to broad platform targeting alone.
Early-stage results showed:
- revenue lift of approximately 16%
- return on ad spend improvement around 16%
- click-through rate improvement near 20%
- lower acquisition costs
- stronger revenue share contribution inside the experiment
But the experiment had only reached partial statistical confidence at the time of analysis. That distinction matters enormously.
Many organizations prematurely scale campaigns before enough data exists to confirm whether performance is sustainable. Strategic experimentation intentionally slows that impulse down. The purpose is not to chase temporary spikes. It is to determine whether the lift can survive over time and across broader budget conditions.
Seasonal Testing
Another experiment involving seasonal summer products revealed something equally important. Order volume nearly doubled versus the control campaign, increasing by more than 90%. At first glance, that sounds like an obvious win. But deeper analysis revealed a more complicated picture.
Average order value declined significantly. Revenue efficiency weakened. Return on ad spend dropped compared to the control. While the campaign generated substantially more purchases, the underlying economics became less efficient because the product mix skewed toward lower-value orders.
This is exactly why experimentation cannot rely on a single metric. A campaign can produce more orders while simultaneously reducing profitability. A platform optimizing purely toward conversion volume might interpret the experiment as successful. But from a business perspective, the quality of revenue matters just as much as quantity.
This is one of the clearest examples of why AI systems require calibration rather than blind trust. The machine optimized effectively toward the signals it received. The question is whether those signals represented the correct business objective.
The Most Valuable 'Failed' Experiment
Another experiment produced the most valuable learning of the quarter despite technically “failing.” The dormant SKU activation experiment attempted to revive more than 600 historically inactive products using predictive audience layering and paid search expansion strategies.
The theory was reasonable: if predictive intelligence could identify hidden buyer intent, then previously ignored inventory might produce incremental revenue opportunities.
Instead, the opposite occurred.
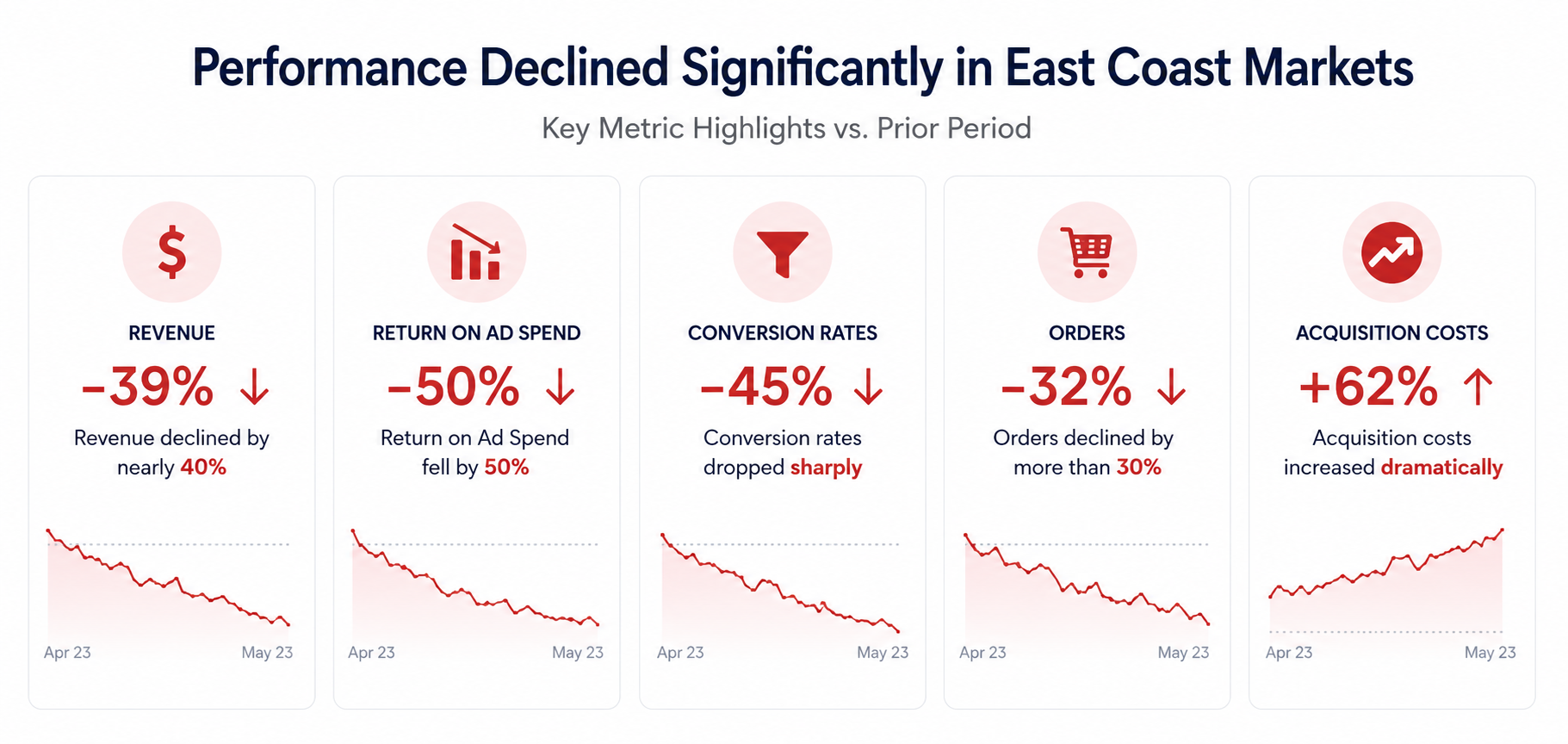
Compared against the control:
- revenue declined by nearly 40%
- return on ad spend fell by 50%
- conversion rates dropped sharply
- orders declined by more than 30%
- acquisition costs increased dramatically
The test reached near-complete statistical confidence quickly enough to validate the result and the campaign was stopped immediately. That outcome demonstrates one of the most important truths in modern AI marketing: AI cannot manufacture demand that fundamentally does not exist.
The dormant SKUs remained dormant for a reason. And this is where strategic experimentation protects organizations financially. Without a controlled testing environment, many brands would continue scaling campaigns like this for months hoping the algorithm would “learn” its way into performance improvement.
Instead, the experimentation framework identified the failure early, isolated the cause, and prevented additional budget erosion.
That is not a failed quarter. The broader achievement across these experiments was not simply individual campaign lift. By maintaining a minimum cadence of two active experiments per month, the organization created a structured feedback loop where:
- winning strategies graduated into evergreen campaigns
- losing strategies were shut down quickly
- predictive audience intelligence improved over time
- acquisition efficiency became more calibrated
- media spend became increasingly intentional
Instead of relying on static annual planning, the marketing system became adaptive. And this framework extends far beyond pet supply ecommerce.
The theory applies especially well to industries with:
- high SKU counts
- repeat purchase behavior
- replenishment cycles
- strong category segmentation
- large product catalogs
- varying customer lifetime value patterns
That includes beauty, supplements, grocery, baby products, apparel, automotive parts, home goods, sporting goods, and subscription commerce. The more frequently customers purchase, the more valuable experimentation becomes because every acquisition decision affects future lifetime value, retention, bundling opportunities, and long-term profitability.
More articles


More Revenue.
Same Spend.
We’re breaking the black box of AI and empowering you with transparent insights to maximize your budget.

